Foundation models have transformed vision and language by learning general-purpose representations from large-scale unlabeled data, yet 3D medical imaging lacks analogous approaches. Existing self-supervised methods rely on low-level reconstruction or contrastive objectives that fail to capture the anatomical semantics critical for medical image analysis, limiting transfer to downstream tasks. We present MASS (MAsk-guided Self-Supervised learning), which treats in-context segmentation as the pretext task for learning general-purpose medical imaging representations. MASS's key insight is that automatically generated class-agnostic masks provide sufficient structural supervision for learning semantically rich representations. By training on thousands of diverse mask proposals spanning anatomical structures and pathological findings, MASS learns what semantically defines medical structures: the holistic combination of appearance, shape, spatial context, and anatomical relationships. We demonstrate effectiveness across data regimes: from small-scale pretraining on individual datasets (20–200 scans) to large-scale multi-modal pretraining on 5K CT, MRI, and PET volumes, all without annotations. MASS demonstrates: (i) few-shot segmentation on novel structures, (ii) matching full supervision with only 20–40% labeled data while outperforming self-supervised baselines by over 20 in Dice score in low-data regimes, and (iii) frozen-encoder classification on unseen pathologies that matches full supervised training with thousands of samples. Mask-guided self-supervised pretraining captures broadly generalizable knowledge, opening a path toward 3D medical imaging foundation models without expert annotations.
🚫 Zero Expert Annotation
MASS uses in-context segmentation as the pretext task with auto-generated class-agnostic masks. No expert annotation cost — yet achieves performance comparable to supervised pretraining, and substantially outperforms reconstruction and contrastive SSL methods.
🧠 In-Context Medical Knowledge
Like LLMs that acquire language understanding through pretraining, MASS acquires medical knowledge (anatomy, morphology, spatial relationships) during self-supervised pretraining — enabling few-shot segmentation directly out of the box, without any finetuning.
📈 Scalable Across Data Regimes
Effective from 20 scans to 5K multi-modal CT, MRI, and PET volumes, with consistent improvements as data scale and diversity increase.
🎯 Few-Shot Power
With only 20–40% labeled data, MASS matches full supervision and outperforms all prior SSL methods by >20 Dice points in low-data regimes.
🔄 Broad Generalization
Frozen-encoder classification on unseen pathologies matches fully supervised training with thousands of labeled samples — knowledge transfers beyond segmentation.
Like LLMs that acquire language understanding through pretraining on unlabeled text, MASS acquires medical imaging knowledge — anatomy, morphology, spatial relationships — entirely through self-supervised pretraining on auto-generated masks. No expert annotations. No supervised finetuning. The pretrained model can directly perform few-shot in-context segmentation out of the box.
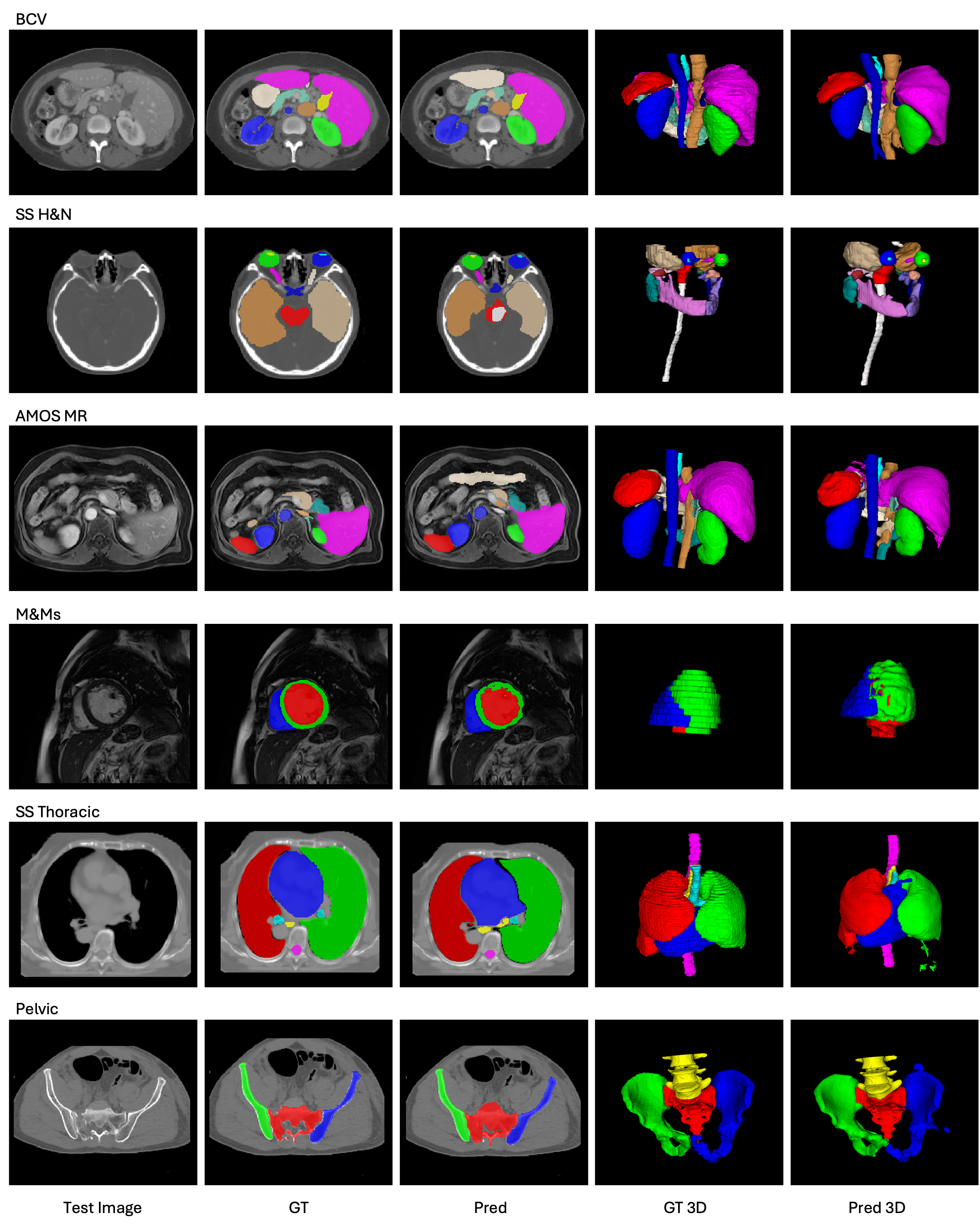
Probing learned knowledge through one-shot in-context inference with the MASS pretrained model (no finetuning). Just as LLMs learn language understanding by predicting tokens on unlabeled text, MASS learns medical imaging understanding by predicting masks on unlabeled scans. After pretraining, the model has internalized broad medical knowledge — given just a single reference image-mask pair, it segments novel structures across diverse body regions (abdomen, head & neck, thorax, pelvis, cardiac) and modalities (CT, MRI) without ever seeing expert annotations. This mirrors the LLM paradigm: pretrain on large-scale unlabeled data to acquire general knowledge, then align with minimal expert supervision for downstream deployment.
We visualize what MASS learns by extracting decoder output features from the pretrained model (without any finetuning) and reducing to 3 channels via PCA for RGB visualization. The results reveal rich, hierarchical anatomical understanding learned entirely from mask-guided self-supervision.
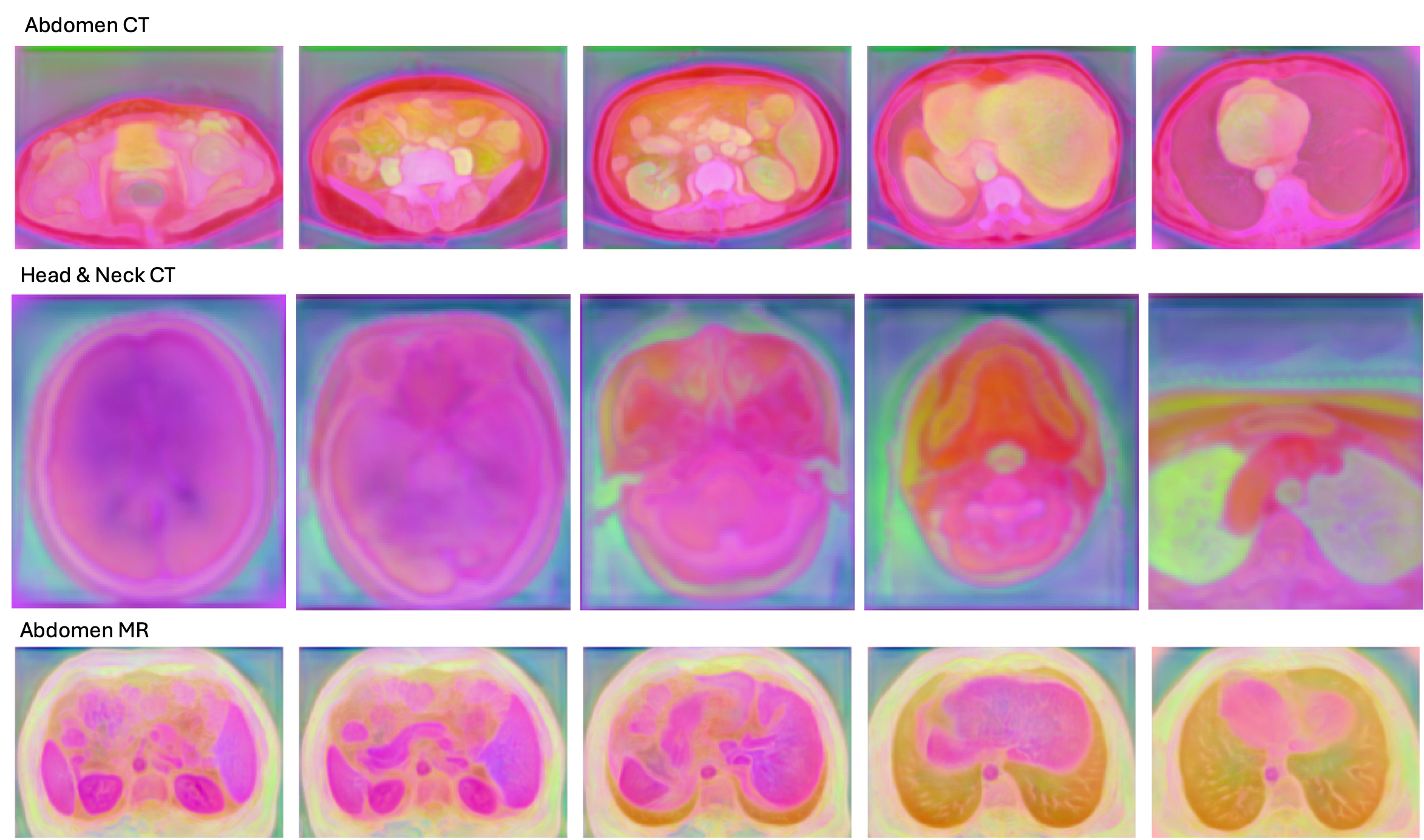
🔍 Clear Anatomical Boundaries
Sharp delineation of organs (kidneys, liver, spleen, heart, lungs), skeletal structures (mandible, skull), and soft tissue compartments (muscles, fat).
🎨 Semantic Consistency
Semantically similar structures share consistent feature patterns — e.g., bilateral kidneys exhibit matching representations, indicating learned semantic concepts, not spatial templates.
🔬 Multi-Granular Understanding
Beyond large organs, MASS captures fine-grained sub-anatomical details: pulmonary vasculature, hepatic vessels, and distinct cardiac chambers — multi-scale knowledge from diverse auto-generated masks.
@article{gao2026learning,
title={Learning Generalizable 3D Medical Image Representations from Mask-Guided Self-Supervision},
author={Gao, Yunhe and Zhang, Yabin and Wang, Chong and Liu, Jiaming and Varma, Maya and Delbrouck, Jean-Benoit and Chaudhari, Akshay and Langlotz, Curtis},
journal={arXiv preprint arXiv:2603.13660},
year={2026}
}